画像処理ライブラリ HALCONのディープラーニング機能は、その性能と高速性により、国内外で多くの活用実績を誇ります。このディープラーニングをさらに高速化させて活用の幅を広げる、【AIアクセラレータ】の特徴と使用方法についてご紹介します。
「Deep Learning Toolで評価を行って精度は出たものの速度が要求を満たさない」
「GPUのランクを落としてハードウェアのコストを下げたい」
「GPUを使わずに、CPU上でディープラーニング推論処理を行いたい」
など、高速化やシステムコストダウンを検討する際に、ぜひお使いいただきたい機能です。AIアクセラレータ機能を使用することで、倍以上の処理時間短縮を実現した計測結果も交えてご紹介します。

AIアクセラレータとは
一般にAIアクセラレータは、ディープラーニングをはじめとするAIの計算処理を高速化するために設計されたハードウェアのことを指します。HALCONにおいては、特定のハードウェアに加え、通常のCPU・GPUでの推論を高速化する仕組みを含めてAIアクセラレータ・インターフェース (AI2) と呼んでいます。
HALCON 24.05 Progressは次の3つのAI2に対応しています。
● TensorRT:NVIDIA製GPU 用
● OpenVINO:Inetl製CPU・GPU・VPU用
● HAILO:専用デバイス Hailo-8での実行用
要求速度やコスト・使用するディープラーニングモデルに合わせて最適なAI2を選ぶことができます。
本稿では、既にお使いのGPU・CPU環境下でさらに高速化することを狙いとして、TensorRTとOpenVINOについてご紹介します。
AIアクセラレータの恩恵
AI2を使用するだけでどの程度の高速化が狙えるのか、まずは次のグラフをご確認ください。
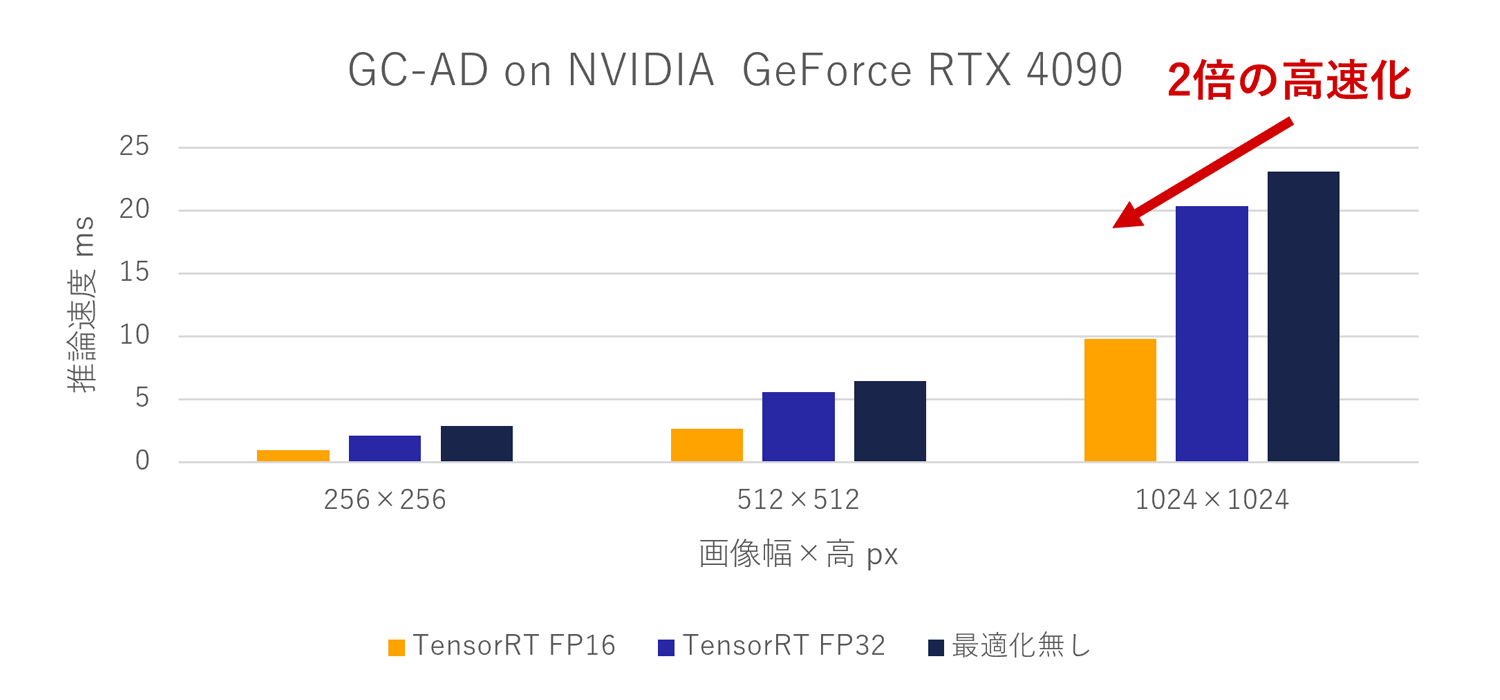
ハイエンドクラスのGPU、NVIDIA GeForce RTX 4090で、画像サイズを変えながらHALCONのグローバルアノマリー検出を適用した結果です。例えば1024×1024の画像では、単体のGPU実行 (紺)では23.1msの実行時間がTensorRT FP16オプション (黄) では9.8msと、実に倍以上の推論速度向上が行われています。また、どの画像サイズであっても、TensorRTを適用することで推論速度の向上が確認できます。
CPUでも高速なディープラーニング推論処理が可能
高速化するのはGPUだけではありません。OpenVINOを使用すると、通常のIntel CPUでの推論速度が向上します。次のグラフは画像分類のEnhanced (高精度) モデルでの推論速度です。

画像サイズ512×512では、通常時 (黒) 15.2msからOpenVINO BF16 (水色) では 5.3msと3倍近く高速化しています。また、画像サイズ224×224では、OpenVINO BF16が2.0ms、2世代前のハイエンドGPUであるRTX 2080 Tiでは3.15msと、GPUを超える速度をCPUでも実現できています。OpenVINO BF16オプションは、HALCON 24.05から一部のデバイスで使用できるようになった機能で、CPUでの推論速度を大幅に向上させています。もちろん現行ハイエンドには及びませんが、小さい画像を対象とするような分類タスクであれば、CPU単体でもGPUと同程度高速に動作することがわかります。いままで追加のコストをかけてGPUで動作させていたアプリケーションも、CPUでの実行ができるかもしれません。
AIアクセラレータの使い方
MVTecが提供する3つのソフトウェアで、お手元にあるディープラーニングモデルをAI2で実行して推論時間を評価する方法をご紹介します。
Deep Learning Tool使用の場合
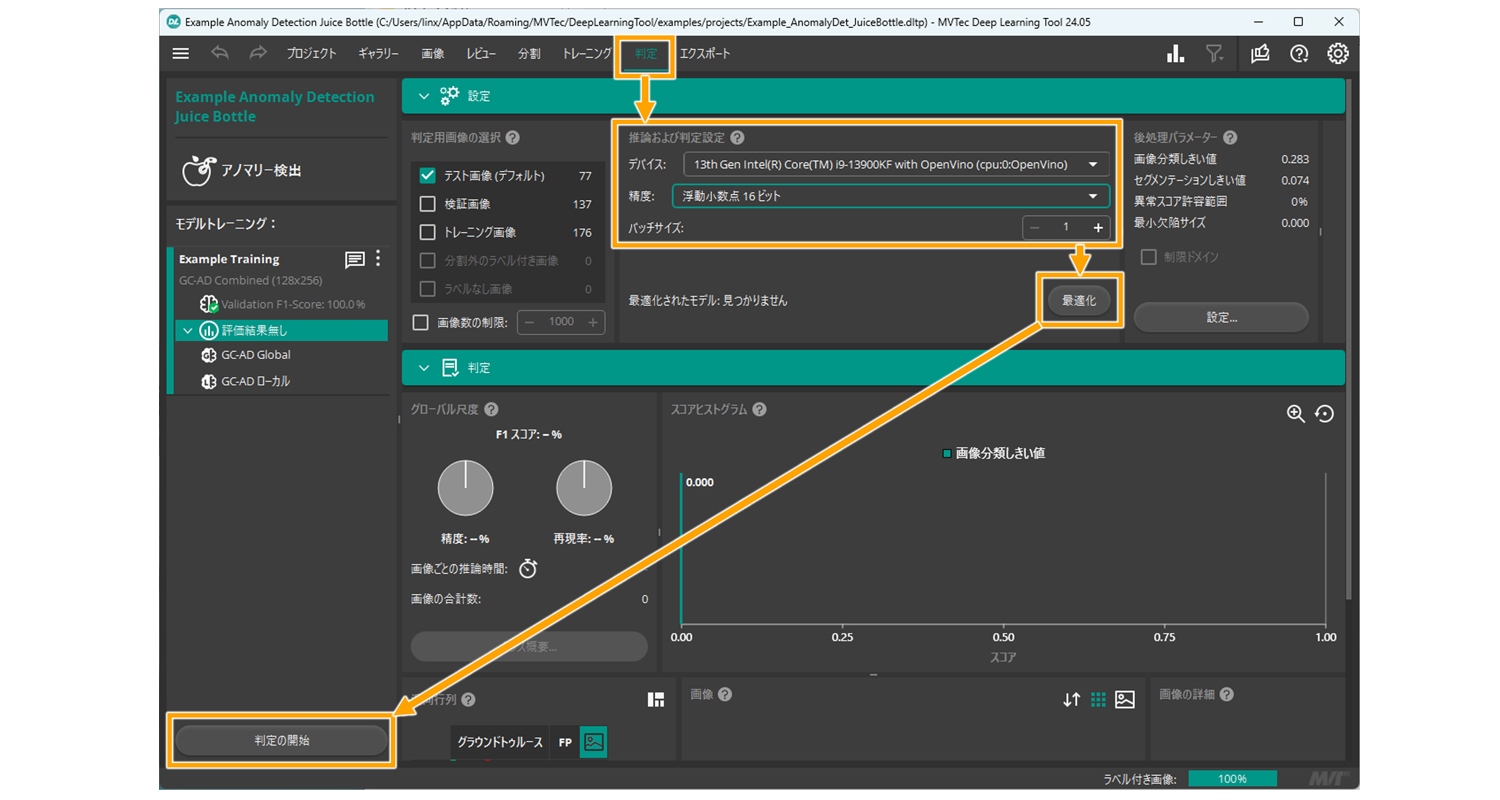
Deep Learning Toolですでに作成したモデルがある場合、わずか4ステップでAI2の評価を行えます。
1. 「判定」タブを開く
2. 「推論及び判定設定」でTensorRTまたはOpenVINOのデバイスを選択したうえで精度とバッチサイズを指定
3. 「最適化」を実行して作成したモデルを最適化 (TensorRTの場合数十秒必要)
4. 「判定の開始」で最適化済みモデルでの精度と推論速度の評価
HALCONの場合
HALCONあるいはDeep Learning Toolで作成したHALCONディープラーニングモデル (.hdlファイル) を読み込んで実行するフローは図のようになります。
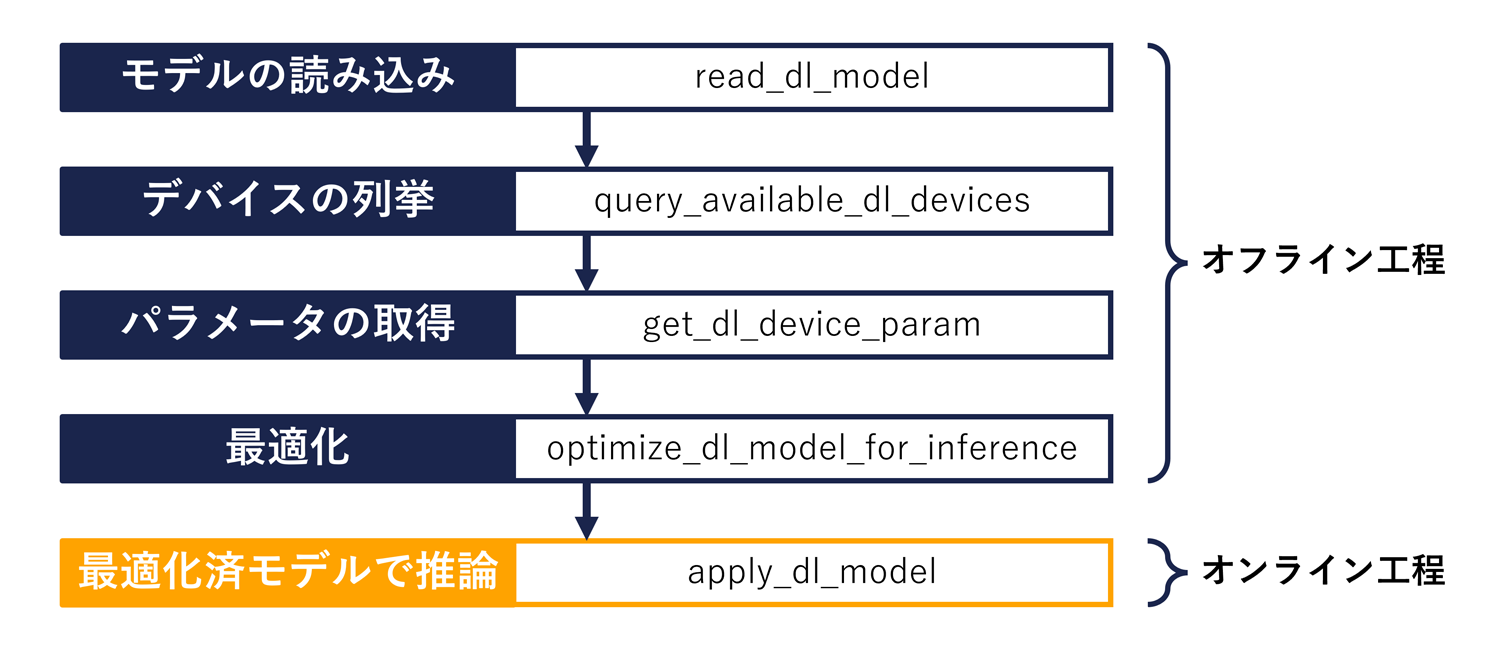
実際のサンプルコードは、よくあるお問い合わせ (https://linx-jp.my.site.com/kb/s/article/000007525) にございます。
MERLICの場合
MERLICでは最適化前のディープラーニングモデル (.hdlファイル) をDeep Learning Toolからエクスポートしていることを前提とします。AI2の設定方法はAIタイプのツールすべてに共通です。
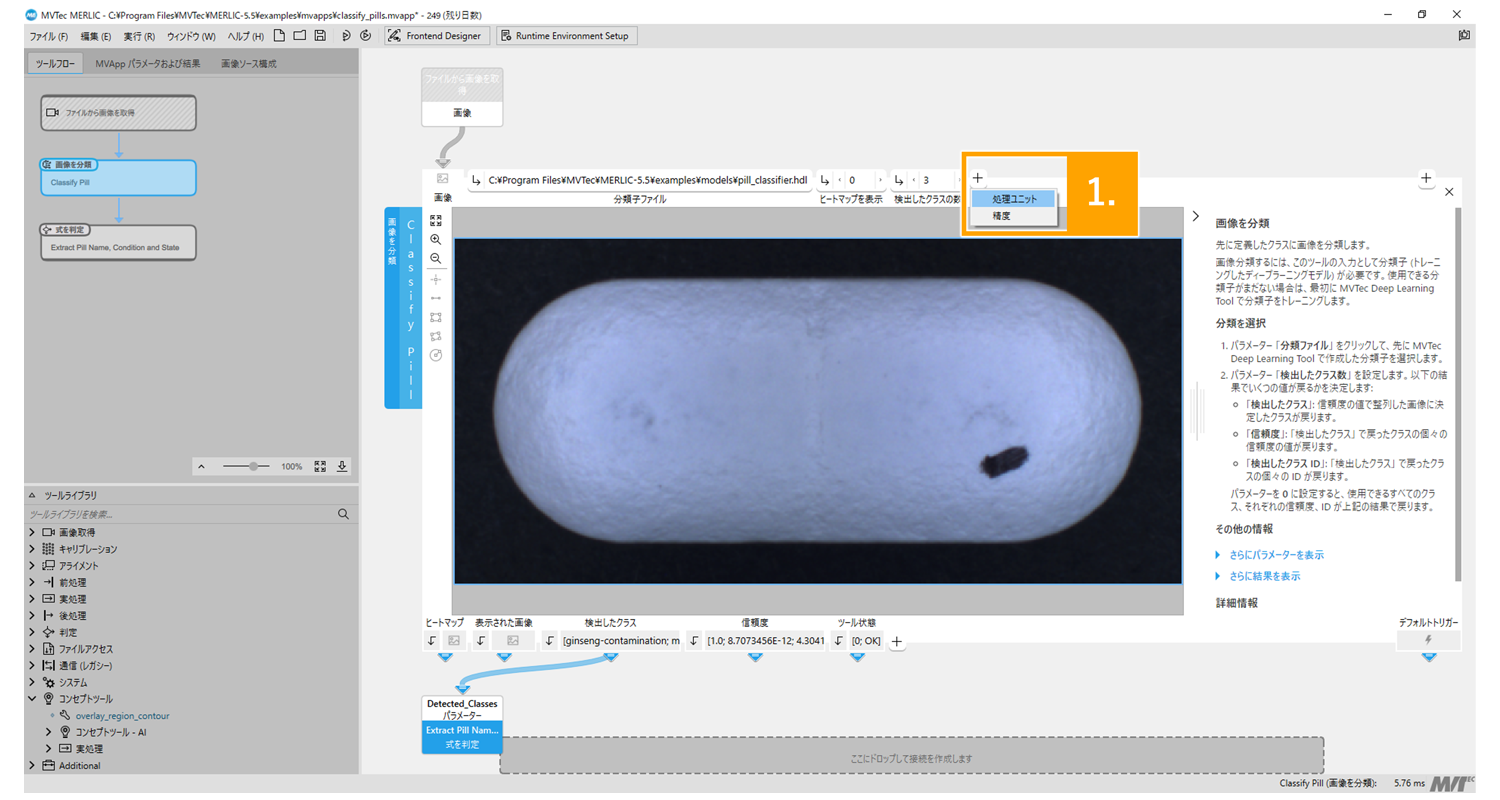
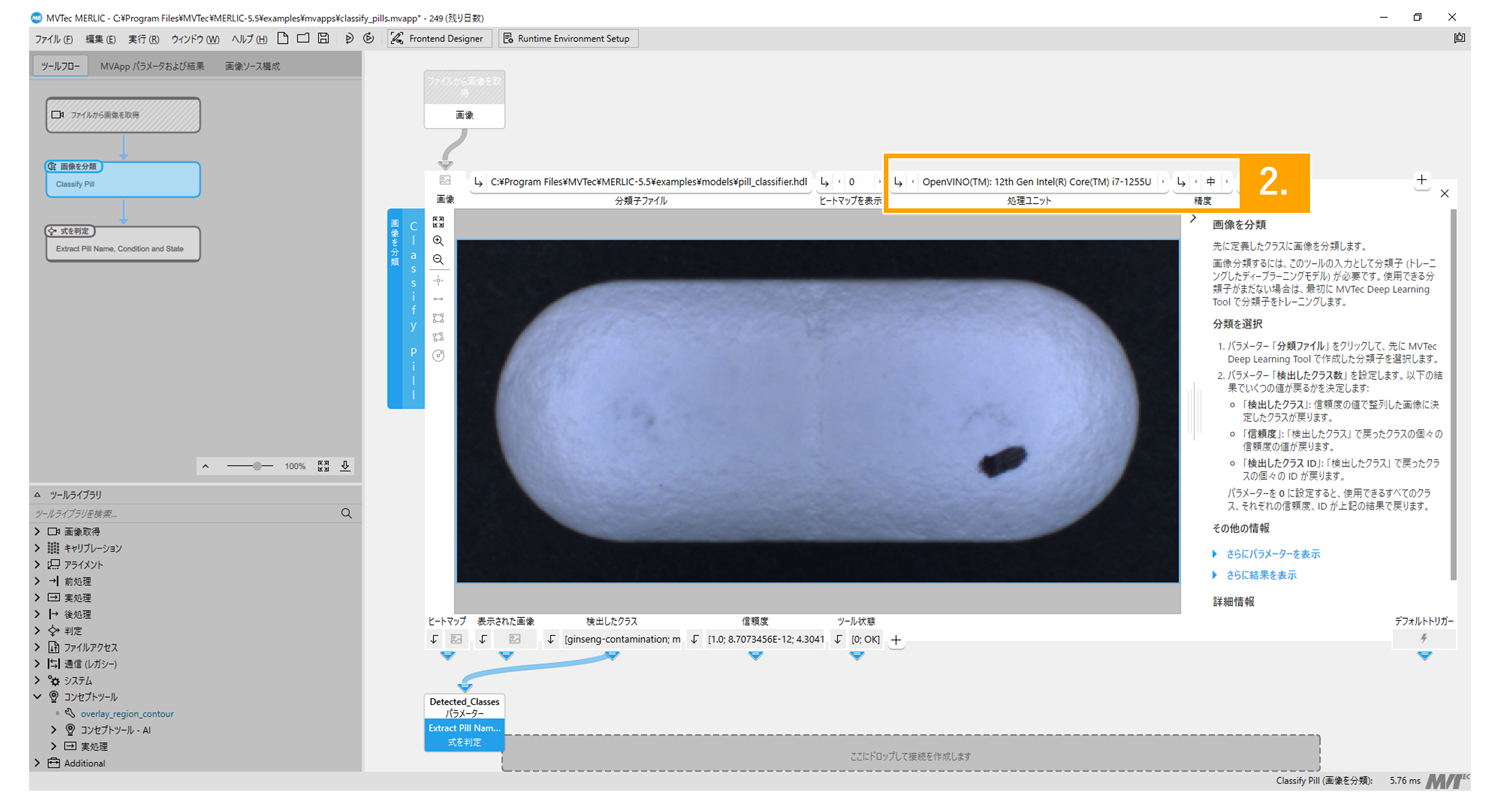
1. AIタイプのツールの入力パラメータで「+」を選択して「処理ユニット」と「精度」の両方を可視化
2. それぞれのパラメータを設定して最適化。最適化済みモデルはmvappファイルに自動保存
HALCONをご検討の方へ
HALCONは、1か月限定で最新バージョンのすべての機能をご使用いただける、Trial Kitをご用意しています。こちらのフォームよりお申込みいただけます。そのほか、「このモデルパラメータのときの速度はどの程度か」「現在のモデルからX%速度向上させたいが実現できるか」といった質問をはじめ、HALCONの使い方などのご相談は弊社サポート窓口までお問合せください。

| HALCON Trial Kitはこちら | お問い合わせはこちら |
ご意見・ご感想募集
LINX Expressに関する要望やご感想を募集しております。下記フォームよりお気軽にご投稿いただけましたら幸いです。

いただいたご意見については今後の運営の参考にさせていただきます。皆様のご投稿お待ちしております。