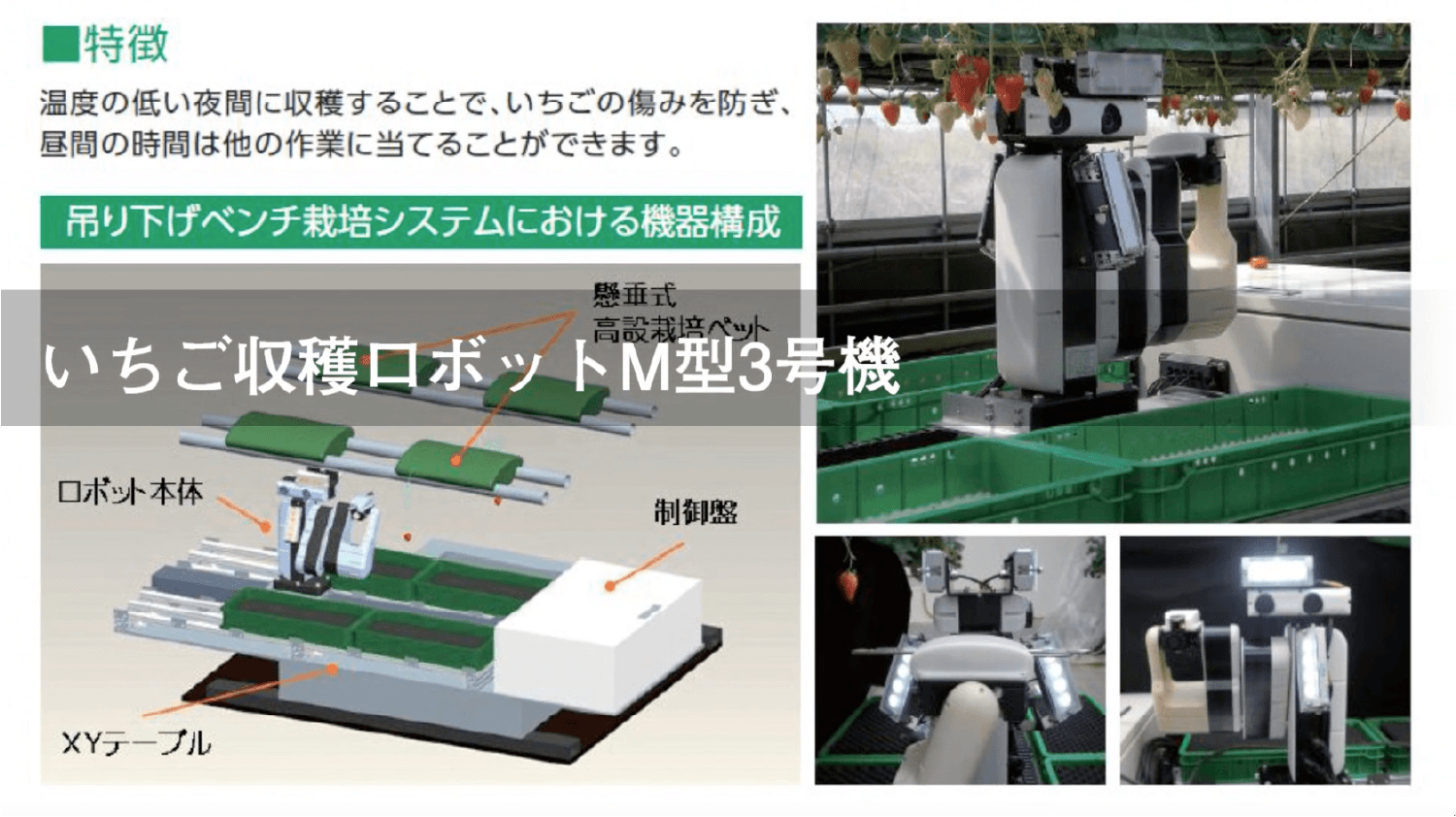
文字認識を行うためには、文字領域の抽出という操作が重要となってきます。HALCONでは、文字領域抽出に使用できる多くの形状処理オペレータ、特徴量抽出オペレータを持っており、文字認識のための前処理を強力にサポートします。文字領域の抽出操作さえ完了すれば、あとはHALCONの持つ文字認識のための関数を用いてプログラミングするだけで文字認識を実現します。HALCONの文字認識は学習フェーズと認識フェーズとに分かれており、学習フェーズにて登録したデータからもっとも信頼性の高い文字とその信頼度を返します。英数字のみならず、学習フェーズにてトレーニングさえ実施すれば、ひらがなや漢字、ロゴなどを認識することもできます。

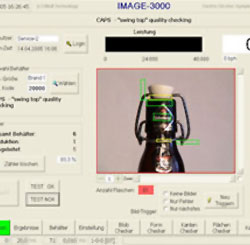
左にあるワインボトルのラベルに対する文字認識の例題では、一見単純そうに見えますが、多くの文字認識システムでは、文字がにじんでいる場合には認識率が低下します。このようなにじみにも対応した文字認識を行うために、HALCONが役立ちます。

最初に文字領域を抽出するために、単純2値化を行います。例題では、グレイ値が0以上95以下のピクセルを抽出していますが、自動的に最適な2値化の値を求めることも可能です。この状態では、文字がそれぞれ隣接する文字と接合しています。

文字の切り出しの前処理のために、穴の塗りつぶしを行います。

文字の切り出しを行うにあたって、文字同士のつながり部分が縦長であるという特徴を用います。矩形構造の要素を持つオープニング処理を行うことにより、領域が文字単位に切り出されていることが確認できます。

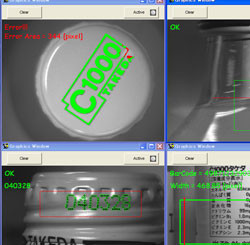
領域の連結成分を計算します。正しく切り出しができたことを確認するために、ここでは色を分けて表示しています。

最後に、文字認識を行います。もちろん、事前にこれら文字の学習データを読み込んでおく必要があります。結果として、010894という数値が得られました。

様々な文字認識の例です。