|
■
HALCON11による効率的なOCRアプリケーション開発
前号のLinX Expressでは、HALCON 11の新機能「OCRトレーニングブラウザ」を紹介しました。この機能により、例えばステンシルフォントなどのHALCONが標準提供していないフォントのデータセットや、「\, -, 1, 2, 3, A, B, C」といった特定の文字のみを含むデータセットの生成を効率よく行えるようになりました。
さらに、HALCON 11で追加された「OCRアシスタント機能」を組み合わせる事で、これまでOCRアプリケーション作成に必要とされてきた手順を大幅に削減することが出来るようになりました。
今号は、これらの新機能「OCRトレーニングブラウザ」と「OCRのアシスタント機能」の活用による、HALCONの効率的なOCR開発の手順を紹介します。
■
OCRアシスタントツール
HALCONの開発環境HDevelopでは、カメラ接続やマッチングなどのよく使われる機能をシンプルなマウス操作で開発できるアシスタント機能を持っています。HALCON 11ではさらにOCRのアシスタント機能が追加され、効率的なOCRアプリケーション開発が行えるようになりました。

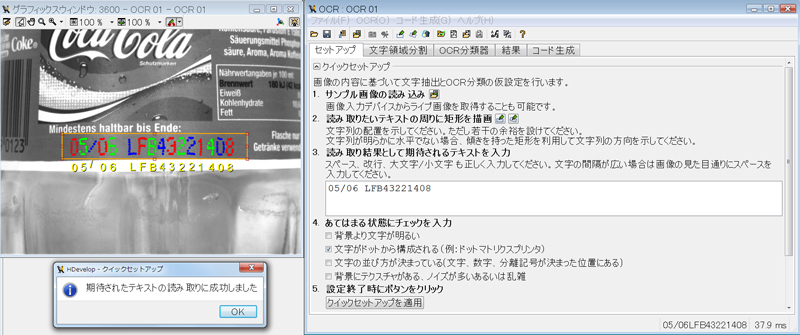
このアシスタント機能の一つとして、OCR分類器の学習機能が搭載されています。この機能により、ユーザー独自の分類器を効率よく開発できるようになりました。これらの新機能を活用した効率的な開発手順を以下に紹介します。
■
ステップ1: 画像からの文字データ抽出
|

|
|
OCRアプリケーションでは、文字を読み取りたい対象物の画像データを準備できるケースが多くあります。この場合、撮影した画像データから文字情報を直接学習させる事で認識精度を高める事が可能です。
二値化、モフォロジー処理などのHALCONの豊富な領域処理により文字領域を取得し、append_ocr_trainfのオペレータにより、文字領域、画像、その文字を何と識別するか登録していきます。画像情報を利用することで、特殊なフォントや標準の文字に含まれない特殊記号も登録が可能となります。
|
|
|
■
ステップ2: OCRトレーニングブラウザによるデータセット管理
|
|
|
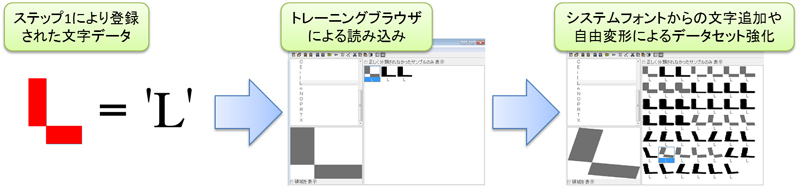
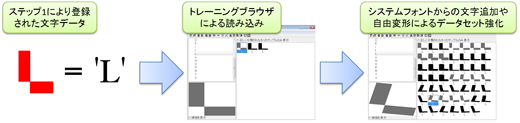
ステップ1による画像からの文字データ取得では、トレーニングに十分なサンプルデータの取得が難しいケースがあります。この場合、前号で紹介したOCRトレーニングブラウザの機能を活用したデータセットの強化が便利です。
もしアプリケーションで利用されるフォントがインストールされている場合、システムフォントから文字を追加し、不足する文字データを補うことが可能です。
さらに、これらの文字データに自由変形を加える事で画像ノイズを加味したデータセットを生成でき、アプリケーションの認識精度を格段に上げる事が可能です。
|
■
ステップ3: OCRアシスタント機能による学習
|
|
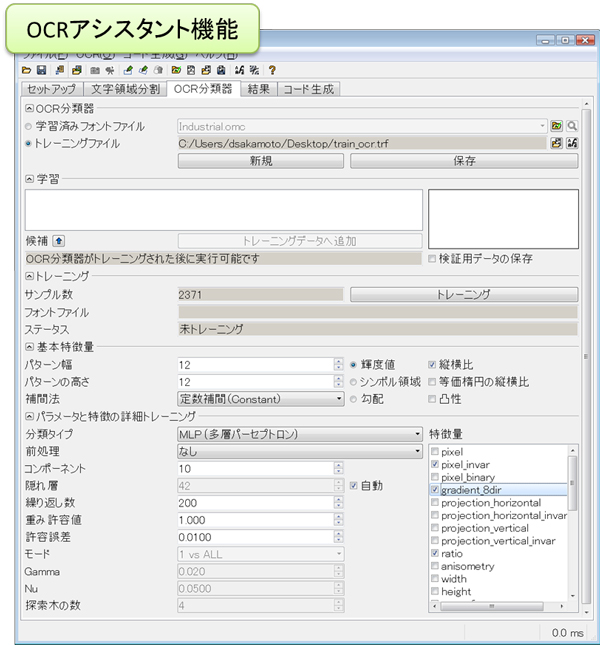
最後に、OCRアシスタントの学習機能によりOCRに必要な分類器を生成します。
OCR分類器のタブより、上記ステップで生成したデータセットを読み込み、トレーニングボタンを押すだけでHALCONが自動的に学習を行い分類器を生成します。この学習では、使用する特徴量、分類アルゴリズム、各種分類パラメータを柔軟に調整できるようになっています。
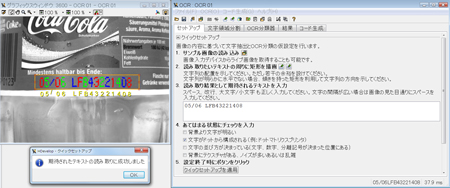
以下のプログラムでは、実際にOCRアシスタント機能で学習させた分類器を用いて文字認識を行い、正しく読み取れている事が確認できます。
|
|